Exploratory data analysis of AMEX Default Prediction Train Data using Dask
Jul 9, 2022
original file is my public notebook on Kaggle:
- https://www.kaggle.com/code/xxxxyyyy80008/amex-default-prediction-eda-of-train-data
This notebook analyzes the train data in the following areas:
- general information:
- file size, number of samples, number of features, data type of each feature.
- statistics
- missing values: features with too many missing values should be dropped.
- for categorical features: distribution of samples in each category.
- numeric features: distribution of data .
- plot out histgraph of both the original data and log tranformed data
- plot the log transformed data will help the check if a feature will benefit from log transformation
key notes:
- train label file has
458,913rows for458,913unique customer ID - train data file has
5,531,451rows for458,913unique customer ID customer_IDis the key to connect train label and data- in train data:
- there are a total of
190columns, including key column'customer_ID'and date column'S_2' - a
customer_IDhas at most 13 rows of data
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
/kaggle/input/amex-train-20220706/train.parquet
/kaggle/input/amex-default-prediction/sample_submission.csv
/kaggle/input/amex-default-prediction/train_data.csv
/kaggle/input/amex-default-prediction/test_data.csv
/kaggle/input/amex-default-prediction/train_labels.csv
import numpy as np
import pandas as pd
import gc
import copy
import os
import sys
from pathlib import Path
from datetime import datetime, date, time, timedelta
from dateutil import relativedelta
import pyarrow.parquet as pq
import pyarrow as pa
import dask.dataframe as dd
import warnings
warnings.filterwarnings("ignore")
pd.options.display.max_rows = 100
pd.options.display.max_columns = 100
import pytorch_lightning as pl
random_seed=1234
pl.seed_everything(random_seed)
1234
%%time
chunksize = 100
train_file = '/kaggle/input/amex-default-prediction/train_data.csv'
with pd.read_csv(train_file, chunksize=chunksize) as reader:
for i, chunk in enumerate(reader):
break
CPU times: user 11.3 ms, sys: 7.81 ms, total: 19.1 ms
Wall time: 18.1 ms
chunk.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100 entries, 0 to 99
Columns: 190 entries, customer_ID to D_145
dtypes: float64(185), int64(1), object(4)
memory usage: 148.6+ KB
all_cols = chunk.columns.tolist()
#cat feats based on information from this page: https://www.kaggle.com/competitions/amex-default-prediction/data
cat_feats = ['B_30', 'B_38', 'D_114', 'D_116', 'D_117', 'D_120', 'D_126', 'D_63', 'D_64', 'D_66', 'D_68']
print(len(all_cols)), print(all_cols)
print(len(cat_feats)), print(cat_feats)
190
['customer_ID', 'S_2', 'P_2', 'D_39', 'B_1', 'B_2', 'R_1', 'S_3', 'D_41', 'B_3', 'D_42', 'D_43', 'D_44', 'B_4', 'D_45', 'B_5', 'R_2', 'D_46', 'D_47', 'D_48', 'D_49', 'B_6', 'B_7', 'B_8', 'D_50', 'D_51', 'B_9', 'R_3', 'D_52', 'P_3', 'B_10', 'D_53', 'S_5', 'B_11', 'S_6', 'D_54', 'R_4', 'S_7', 'B_12', 'S_8', 'D_55', 'D_56', 'B_13', 'R_5', 'D_58', 'S_9', 'B_14', 'D_59', 'D_60', 'D_61', 'B_15', 'S_11', 'D_62', 'D_63', 'D_64', 'D_65', 'B_16', 'B_17', 'B_18', 'B_19', 'D_66', 'B_20', 'D_68', 'S_12', 'R_6', 'S_13', 'B_21', 'D_69', 'B_22', 'D_70', 'D_71', 'D_72', 'S_15', 'B_23', 'D_73', 'P_4', 'D_74', 'D_75', 'D_76', 'B_24', 'R_7', 'D_77', 'B_25', 'B_26', 'D_78', 'D_79', 'R_8', 'R_9', 'S_16', 'D_80', 'R_10', 'R_11', 'B_27', 'D_81', 'D_82', 'S_17', 'R_12', 'B_28', 'R_13', 'D_83', 'R_14', 'R_15', 'D_84', 'R_16', 'B_29', 'B_30', 'S_18', 'D_86', 'D_87', 'R_17', 'R_18', 'D_88', 'B_31', 'S_19', 'R_19', 'B_32', 'S_20', 'R_20', 'R_21', 'B_33', 'D_89', 'R_22', 'R_23', 'D_91', 'D_92', 'D_93', 'D_94', 'R_24', 'R_25', 'D_96', 'S_22', 'S_23', 'S_24', 'S_25', 'S_26', 'D_102', 'D_103', 'D_104', 'D_105', 'D_106', 'D_107', 'B_36', 'B_37', 'R_26', 'R_27', 'B_38', 'D_108', 'D_109', 'D_110', 'D_111', 'B_39', 'D_112', 'B_40', 'S_27', 'D_113', 'D_114', 'D_115', 'D_116', 'D_117', 'D_118', 'D_119', 'D_120', 'D_121', 'D_122', 'D_123', 'D_124', 'D_125', 'D_126', 'D_127', 'D_128', 'D_129', 'B_41', 'B_42', 'D_130', 'D_131', 'D_132', 'D_133', 'R_28', 'D_134', 'D_135', 'D_136', 'D_137', 'D_138', 'D_139', 'D_140', 'D_141', 'D_142', 'D_143', 'D_144', 'D_145']
11
['B_30', 'B_38', 'D_114', 'D_116', 'D_117', 'D_120', 'D_126', 'D_63', 'D_64', 'D_66', 'D_68']
(None, None)
load the train parquet file
%%time
train_labels = pd.read_csv('/kaggle/input/amex-default-prediction/train_labels.csv')
print(train_labels.shape)
display(train_labels.head(2))
(458913, 2)
| customer_ID | target | |
|---|---|---|
| 0 | 0000099d6bd597052cdcda90ffabf56573fe9d7c79be5f... | 0 |
| 1 | 00000fd6641609c6ece5454664794f0340ad84dddce9a2... | 0 |
CPU times: user 638 ms, sys: 207 ms, total: 844 ms
Wall time: 843 ms
train_labels.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 458913 entries, 0 to 458912
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 customer_ID 458913 non-null object
1 target 458913 non-null int64
dtypes: int64(1), object(1)
memory usage: 7.0+ MB
train_labels['customer_ID'].nunique()
458913
calcuate the na cnt
%%time
train_file = '/kaggle/input/amex-train-20220706/train.parquet'
CPU times: user 3 µs, sys: 1 µs, total: 4 µs
Wall time: 15.5 µs
%%time df = pd.read_parquet(train_file, columns=[‘customer_ID'], engine='pyarrow')
%%time
df = dd.read_parquet(train_file, columns=['customer_ID'], engine='pyarrow')
total_cnt = df.count().compute().values[0]
unique_cnt = df.compute().nunique().values[0]
print(total_cnt, unique_cnt)
del df
gc.collect()
5531451 458913
CPU times: user 4.32 s, sys: 2.24 s, total: 6.56 s
Wall time: 6.43 s
150
%%time
data_types = []
for c in all_cols:
df = dd.read_parquet(train_file, columns=[c], engine='pyarrow')
data_types.append([c, df.dtypes.values[0], df.isna().sum().compute().values[0], df.nunique().compute().values[0]])
del df
gc.collect()
CPU times: user 6min 9s, sys: 52.4 s, total: 7min 1s
Wall time: 8min 5s
nacnt = pd.DataFrame(data_types, columns=['feat', 'dtype', 'na_cnt', 'nunique'])
nacnt['na_pct'] = 100*nacnt['na_cnt']/total_cnt
nacnt.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 190 entries, 108 to 95
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 feat 190 non-null object
1 dtype 190 non-null object
2 na_cnt 190 non-null int64
3 nunique 190 non-null int64
4 na_pct 190 non-null float64
dtypes: float64(1), int64(2), object(2)
memory usage: 8.9+ KB
%%time
nacnt.to_csv('nacnt.csv', sep='|', index=False) #save data into a csv file for later use
CPU times: user 4.03 ms, sys: 2.86 ms, total: 6.88 ms
Wall time: 10.2 ms
nacnt['dtype'].value_counts()
float32 185
object 4
int32 1
Name: dtype, dtype: int64
nacnt['na_pct'].hist(bins=50)
<AxesSubplot:>
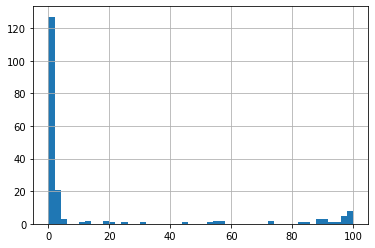
base on unique number of values per feature to potential categorical feature list
D_87: has only one unique value but most samples have missing values. thus this feature should not be considered as categorical features and will be dropped.B_31: has no missing value and only two possible values. this feature will be considered as a categorical feature
nacnt[nacnt['nunique']<=100]
| feat | dtype | na_cnt | nunique | na_pct | |
|---|---|---|---|---|---|
| 53 | D_63 | object | 0 | 6 | 0.000000 |
| 54 | D_64 | object | 217442 | 4 | 3.931012 |
| 60 | D_66 | float32 | 4908097 | 2 | 88.730733 |
| 62 | D_68 | float32 | 216503 | 7 | 3.914036 |
| 105 | B_30 | float32 | 2016 | 3 | 0.036446 |
| 108 | D_87 | float32 | 5527586 | 1 | 99.930127 |
| 112 | B_31 | int32 | 0 | 2 | 0.000000 |
| 145 | B_38 | float32 | 2016 | 7 | 0.036446 |
| 155 | D_114 | float32 | 176716 | 2 | 3.194749 |
| 157 | D_116 | float32 | 176716 | 2 | 3.194749 |
| 158 | D_117 | float32 | 176716 | 7 | 3.194749 |
| 161 | D_120 | float32 | 176716 | 2 | 3.194749 |
| 167 | D_126 | float32 | 116816 | 3 | 2.111851 |
potential_cat_feats = nacnt[nacnt['nunique']<=100]['feat'].values.tolist()
print(potential_cat_feats)
print(set(potential_cat_feats)-set(cat_feats))
['D_63', 'D_64', 'D_66', 'D_68', 'B_30', 'D_87', 'B_31', 'B_38', 'D_114', 'D_116', 'D_117', 'D_120', 'D_126']
{'B_31', 'D_87'}
missing values
- features with too much missing values will be dropped
>=80%samples missing value: 23 featuresmissing80 = ['D_87', 'D_88', 'D_108', 'D_111', 'D_110', 'B_39', 'D_73', 'B_42', 'D_134', 'D_135', 'D_136', 'D_137', 'D_138', 'R_9', 'B_29', 'D_106', 'D_132', 'D_49', 'R_26', 'D_76', 'D_66', 'D_42', 'D_142']>=50%samples missing value: 30 featuresmissing50 = ['D_87', 'D_88', 'D_108', 'D_111', 'D_110', 'B_39', 'D_73', 'B_42', 'D_134', 'D_135', 'D_136', 'D_137', 'D_138', 'R_9', 'B_29', 'D_106', 'D_132', 'D_49', 'R_26', 'D_76', 'D_66', 'D_42', 'D_142', 'D_53', 'D_82', 'D_50', 'B_17', 'D_105', 'D_56', 'S_9']>=20%samples missing value: 34 featuresmissing20 = ['D_87', 'D_88', 'D_108', 'D_111', 'D_110', 'B_39', 'D_73', 'B_42', 'D_134', 'D_135', 'D_136', 'D_137', 'D_138', 'R_9', 'B_29', 'D_106', 'D_132', 'D_49', 'R_26', 'D_76', 'D_66', 'D_42', 'D_142', 'D_53', 'D_82', 'D_50', 'B_17', 'D_105', 'D_56', 'S_9', 'D_77', 'D_43', 'S_27', 'D_46']>=10%samples missing value: 39 faturesmissing10 = ['D_87', 'D_88', 'D_108', 'D_111', 'D_110', 'B_39', 'D_73', 'B_42', 'D_134', 'D_135', 'D_136', 'D_137', 'D_138', 'R_9', 'B_29', 'D_106', 'D_132', 'D_49', 'R_26', 'D_76', 'D_66', 'D_42', 'D_142', 'D_53', 'D_82', 'D_50', 'B_17', 'D_105', 'D_56', 'S_9', 'D_77', 'D_43', 'S_27', 'D_46', 'S_7', 'S_3', 'D_62', 'D_48', 'D_61']
nacnt.sort_values(by='na_pct', ascending=False, inplace=True)
nacnt.head(20)
| feat | dtype | na_cnt | nunique | na_pct | |
|---|---|---|---|---|---|
| 108 | D_87 | float32 | 5527586 | 1 | 99.930127 |
| 111 | D_88 | float32 | 5525447 | 6004 | 99.891457 |
| 146 | D_108 | float32 | 5502513 | 28902 | 99.476846 |
| 149 | D_111 | float32 | 5500117 | 27968 | 99.433530 |
| 148 | D_110 | float32 | 5500117 | 30406 | 99.433530 |
| 150 | B_39 | float32 | 5497819 | 33557 | 99.391986 |
| 74 | D_73 | float32 | 5475595 | 55802 | 98.990211 |
| 172 | B_42 | float32 | 5459973 | 71434 | 98.707789 |
| 178 | D_134 | float32 | 5336752 | 192523 | 96.480146 |
| 179 | D_135 | float32 | 5336752 | 193754 | 96.480146 |
| 180 | D_136 | float32 | 5336752 | 175899 | 96.480146 |
| 181 | D_137 | float32 | 5336752 | 193810 | 96.480146 |
| 182 | D_138 | float32 | 5336752 | 186987 | 96.480146 |
| 87 | R_9 | float32 | 5218918 | 278226 | 94.349891 |
| 104 | B_29 | float32 | 5150035 | 378319 | 93.104594 |
| 139 | D_106 | float32 | 4990102 | 526748 | 90.213255 |
| 175 | D_132 | float32 | 4988874 | 538748 | 90.191055 |
| 20 | D_49 | float32 | 4985917 | 540617 | 90.137597 |
| 143 | R_26 | float32 | 4922146 | 601763 | 88.984717 |
| 78 | D_76 | float32 | 4908954 | 619107 | 88.746226 |
print(nacnt[nacnt['na_pct']>=80].shape)
missing80 = nacnt[nacnt['na_pct']>=80]['feat'].values.tolist()
print('number of features with >=80% samples missing values: ', len(missing80))
print(missing80)
nacnt[nacnt['na_pct']>=80]
(23, 5)
number of features with >=80% samples missing values: 23
['D_87', 'D_88', 'D_108', 'D_111', 'D_110', 'B_39', 'D_73', 'B_42', 'D_134', 'D_135', 'D_136', 'D_137', 'D_138', 'R_9', 'B_29', 'D_106', 'D_132', 'D_49', 'R_26', 'D_76', 'D_66', 'D_42', 'D_142']
| feat | dtype | na_cnt | nunique | na_pct | |
|---|---|---|---|---|---|
| 108 | D_87 | float32 | 5527586 | 1 | 99.930127 |
| 111 | D_88 | float32 | 5525447 | 6004 | 99.891457 |
| 146 | D_108 | float32 | 5502513 | 28902 | 99.476846 |
| 149 | D_111 | float32 | 5500117 | 27968 | 99.433530 |
| 148 | D_110 | float32 | 5500117 | 30406 | 99.433530 |
| 150 | B_39 | float32 | 5497819 | 33557 | 99.391986 |
| 74 | D_73 | float32 | 5475595 | 55802 | 98.990211 |
| 172 | B_42 | float32 | 5459973 | 71434 | 98.707789 |
| 178 | D_134 | float32 | 5336752 | 192523 | 96.480146 |
| 179 | D_135 | float32 | 5336752 | 193754 | 96.480146 |
| 180 | D_136 | float32 | 5336752 | 175899 | 96.480146 |
| 181 | D_137 | float32 | 5336752 | 193810 | 96.480146 |
| 182 | D_138 | float32 | 5336752 | 186987 | 96.480146 |
| 87 | R_9 | float32 | 5218918 | 278226 | 94.349891 |
| 104 | B_29 | float32 | 5150035 | 378319 | 93.104594 |
| 139 | D_106 | float32 | 4990102 | 526748 | 90.213255 |
| 175 | D_132 | float32 | 4988874 | 538748 | 90.191055 |
| 20 | D_49 | float32 | 4985917 | 540617 | 90.137597 |
| 143 | R_26 | float32 | 4922146 | 601763 | 88.984717 |
| 78 | D_76 | float32 | 4908954 | 619107 | 88.746226 |
| 60 | D_66 | float32 | 4908097 | 2 | 88.730733 |
| 10 | D_42 | float32 | 4740137 | 785339 | 85.694278 |
| 186 | D_142 | float32 | 4587043 | 926344 | 82.926577 |
print(nacnt[nacnt['na_pct']>=50].shape)
missing50 = nacnt[nacnt['na_pct']>=50]['feat'].values.tolist()
print('number of features with >=50% samples missing values: ', len(missing50))
print(missing50)
nacnt[nacnt['na_pct']>=50]
(30, 5)
number of features with >=50% samples missing values: 30
['D_87', 'D_88', 'D_108', 'D_111', 'D_110', 'B_39', 'D_73', 'B_42', 'D_134', 'D_135', 'D_136', 'D_137', 'D_138', 'R_9', 'B_29', 'D_106', 'D_132', 'D_49', 'R_26', 'D_76', 'D_66', 'D_42', 'D_142', 'D_53', 'D_82', 'D_50', 'B_17', 'D_105', 'D_56', 'S_9']
| feat | dtype | na_cnt | nunique | na_pct | |
|---|---|---|---|---|---|
| 108 | D_87 | float32 | 5527586 | 1 | 99.930127 |
| 111 | D_88 | float32 | 5525447 | 6004 | 99.891457 |
| 146 | D_108 | float32 | 5502513 | 28902 | 99.476846 |
| 149 | D_111 | float32 | 5500117 | 27968 | 99.433530 |
| 148 | D_110 | float32 | 5500117 | 30406 | 99.433530 |
| 150 | B_39 | float32 | 5497819 | 33557 | 99.391986 |
| 74 | D_73 | float32 | 5475595 | 55802 | 98.990211 |
| 172 | B_42 | float32 | 5459973 | 71434 | 98.707789 |
| 178 | D_134 | float32 | 5336752 | 192523 | 96.480146 |
| 179 | D_135 | float32 | 5336752 | 193754 | 96.480146 |
| 180 | D_136 | float32 | 5336752 | 175899 | 96.480146 |
| 181 | D_137 | float32 | 5336752 | 193810 | 96.480146 |
| 182 | D_138 | float32 | 5336752 | 186987 | 96.480146 |
| 87 | R_9 | float32 | 5218918 | 278226 | 94.349891 |
| 104 | B_29 | float32 | 5150035 | 378319 | 93.104594 |
| 139 | D_106 | float32 | 4990102 | 526748 | 90.213255 |
| 175 | D_132 | float32 | 4988874 | 538748 | 90.191055 |
| 20 | D_49 | float32 | 4985917 | 540617 | 90.137597 |
| 143 | R_26 | float32 | 4922146 | 601763 | 88.984717 |
| 78 | D_76 | float32 | 4908954 | 619107 | 88.746226 |
| 60 | D_66 | float32 | 4908097 | 2 | 88.730733 |
| 10 | D_42 | float32 | 4740137 | 785339 | 85.694278 |
| 186 | D_142 | float32 | 4587043 | 926344 | 82.926577 |
| 31 | D_53 | float32 | 4084585 | 1428989 | 73.842921 |
| 94 | D_82 | float32 | 4058614 | 377661 | 73.373406 |
| 24 | D_50 | float32 | 3142402 | 2306378 | 56.809723 |
| 57 | B_17 | float32 | 3137598 | 1592707 | 56.722874 |
| 138 | D_105 | float32 | 3021431 | 2414778 | 54.622756 |
| 41 | D_56 | float32 | 2990943 | 2446769 | 54.071581 |
| 45 | S_9 | float32 | 2933643 | 2531874 | 53.035686 |
print(nacnt[nacnt['na_pct']>=20].shape)
missing20 = nacnt[nacnt['na_pct']>=20]['feat'].values.tolist()
print('number of features with >=20% samples missing values: ', len(missing20))
print(missing20)
nacnt[nacnt['na_pct']>=20]
(34, 5)
number of features with >=20% samples missing values: 34
['D_87', 'D_88', 'D_108', 'D_111', 'D_110', 'B_39', 'D_73', 'B_42', 'D_134', 'D_135', 'D_136', 'D_137', 'D_138', 'R_9', 'B_29', 'D_106', 'D_132', 'D_49', 'R_26', 'D_76', 'D_66', 'D_42', 'D_142', 'D_53', 'D_82', 'D_50', 'B_17', 'D_105', 'D_56', 'S_9', 'D_77', 'D_43', 'S_27', 'D_46']
| feat | dtype | na_cnt | nunique | na_pct | |
|---|---|---|---|---|---|
| 108 | D_87 | float32 | 5527586 | 1 | 99.930127 |
| 111 | D_88 | float32 | 5525447 | 6004 | 99.891457 |
| 146 | D_108 | float32 | 5502513 | 28902 | 99.476846 |
| 149 | D_111 | float32 | 5500117 | 27968 | 99.433530 |
| 148 | D_110 | float32 | 5500117 | 30406 | 99.433530 |
| 150 | B_39 | float32 | 5497819 | 33557 | 99.391986 |
| 74 | D_73 | float32 | 5475595 | 55802 | 98.990211 |
| 172 | B_42 | float32 | 5459973 | 71434 | 98.707789 |
| 178 | D_134 | float32 | 5336752 | 192523 | 96.480146 |
| 179 | D_135 | float32 | 5336752 | 193754 | 96.480146 |
| 180 | D_136 | float32 | 5336752 | 175899 | 96.480146 |
| 181 | D_137 | float32 | 5336752 | 193810 | 96.480146 |
| 182 | D_138 | float32 | 5336752 | 186987 | 96.480146 |
| 87 | R_9 | float32 | 5218918 | 278226 | 94.349891 |
| 104 | B_29 | float32 | 5150035 | 378319 | 93.104594 |
| 139 | D_106 | float32 | 4990102 | 526748 | 90.213255 |
| 175 | D_132 | float32 | 4988874 | 538748 | 90.191055 |
| 20 | D_49 | float32 | 4985917 | 540617 | 90.137597 |
| 143 | R_26 | float32 | 4922146 | 601763 | 88.984717 |
| 78 | D_76 | float32 | 4908954 | 619107 | 88.746226 |
| 60 | D_66 | float32 | 4908097 | 2 | 88.730733 |
| 10 | D_42 | float32 | 4740137 | 785339 | 85.694278 |
| 186 | D_142 | float32 | 4587043 | 926344 | 82.926577 |
| 31 | D_53 | float32 | 4084585 | 1428989 | 73.842921 |
| 94 | D_82 | float32 | 4058614 | 377661 | 73.373406 |
| 24 | D_50 | float32 | 3142402 | 2306378 | 56.809723 |
| 57 | B_17 | float32 | 3137598 | 1592707 | 56.722874 |
| 138 | D_105 | float32 | 3021431 | 2414778 | 54.622756 |
| 41 | D_56 | float32 | 2990943 | 2446769 | 54.071581 |
| 45 | S_9 | float32 | 2933643 | 2531874 | 53.035686 |
| 81 | D_77 | float32 | 2513912 | 2859646 | 45.447605 |
| 11 | D_43 | float32 | 1658396 | 3708893 | 29.981211 |
| 153 | S_27 | float32 | 1400935 | 3885609 | 25.326718 |
| 17 | D_46 | float32 | 1211699 | 3388402 | 21.905627 |
print(nacnt[nacnt['na_pct']>=10].shape)
missing10 = nacnt[nacnt['na_pct']>=10]['feat'].values.tolist()
print('number of features with >=10% samples missing values: ', len(missing10))
print(missing10)
nacnt[nacnt['na_pct']>=10]
(39, 5)
number of features with >=10% samples missing values: 39
['D_87', 'D_88', 'D_108', 'D_111', 'D_110', 'B_39', 'D_73', 'B_42', 'D_134', 'D_135', 'D_136', 'D_137', 'D_138', 'R_9', 'B_29', 'D_106', 'D_132', 'D_49', 'R_26', 'D_76', 'D_66', 'D_42', 'D_142', 'D_53', 'D_82', 'D_50', 'B_17', 'D_105', 'D_56', 'S_9', 'D_77', 'D_43', 'S_27', 'D_46', 'S_7', 'S_3', 'D_62', 'D_48', 'D_61']
| feat | dtype | na_cnt | nunique | na_pct | |
|---|---|---|---|---|---|
| 108 | D_87 | float32 | 5527586 | 1 | 99.930127 |
| 111 | D_88 | float32 | 5525447 | 6004 | 99.891457 |
| 146 | D_108 | float32 | 5502513 | 28902 | 99.476846 |
| 149 | D_111 | float32 | 5500117 | 27968 | 99.433530 |
| 148 | D_110 | float32 | 5500117 | 30406 | 99.433530 |
| 150 | B_39 | float32 | 5497819 | 33557 | 99.391986 |
| 74 | D_73 | float32 | 5475595 | 55802 | 98.990211 |
| 172 | B_42 | float32 | 5459973 | 71434 | 98.707789 |
| 178 | D_134 | float32 | 5336752 | 192523 | 96.480146 |
| 179 | D_135 | float32 | 5336752 | 193754 | 96.480146 |
| 180 | D_136 | float32 | 5336752 | 175899 | 96.480146 |
| 181 | D_137 | float32 | 5336752 | 193810 | 96.480146 |
| 182 | D_138 | float32 | 5336752 | 186987 | 96.480146 |
| 87 | R_9 | float32 | 5218918 | 278226 | 94.349891 |
| 104 | B_29 | float32 | 5150035 | 378319 | 93.104594 |
| 139 | D_106 | float32 | 4990102 | 526748 | 90.213255 |
| 175 | D_132 | float32 | 4988874 | 538748 | 90.191055 |
| 20 | D_49 | float32 | 4985917 | 540617 | 90.137597 |
| 143 | R_26 | float32 | 4922146 | 601763 | 88.984717 |
| 78 | D_76 | float32 | 4908954 | 619107 | 88.746226 |
| 60 | D_66 | float32 | 4908097 | 2 | 88.730733 |
| 10 | D_42 | float32 | 4740137 | 785339 | 85.694278 |
| 186 | D_142 | float32 | 4587043 | 926344 | 82.926577 |
| 31 | D_53 | float32 | 4084585 | 1428989 | 73.842921 |
| 94 | D_82 | float32 | 4058614 | 377661 | 73.373406 |
| 24 | D_50 | float32 | 3142402 | 2306378 | 56.809723 |
| 57 | B_17 | float32 | 3137598 | 1592707 | 56.722874 |
| 138 | D_105 | float32 | 3021431 | 2414778 | 54.622756 |
| 41 | D_56 | float32 | 2990943 | 2446769 | 54.071581 |
| 45 | S_9 | float32 | 2933643 | 2531874 | 53.035686 |
| 81 | D_77 | float32 | 2513912 | 2859646 | 45.447605 |
| 11 | D_43 | float32 | 1658396 | 3708893 | 29.981211 |
| 153 | S_27 | float32 | 1400935 | 3885609 | 25.326718 |
| 17 | D_46 | float32 | 1211699 | 3388402 | 21.905627 |
| 37 | S_7 | float32 | 1020544 | 4185390 | 18.449843 |
| 7 | S_3 | float32 | 1020544 | 4004312 | 18.449843 |
| 52 | D_62 | float32 | 758161 | 4519358 | 13.706367 |
| 19 | D_48 | float32 | 718725 | 4534865 | 12.993426 |
| 49 | D_61 | float32 | 598052 | 4529133 | 10.811847 |
categorical features
cat_feats = ['B_30', 'B_38', 'D_114', 'D_116', 'D_117', 'D_120', 'D_126', 'D_63', 'D_64', 'D_66', 'D_68']
%%time
for c in cat_feats:
df = dd.read_parquet(train_file, columns=[c], engine='pyarrow')
print(c, '-'*100)
print(df[c].nunique().compute())
display(df[c].value_counts().compute().sort_index())
del df
gc.collect()
B_30 ----------------------------------------------------------------------------------------------------
3
0.0 4710663
1.0 763955
2.0 54817
Name: B_30, dtype: int64
B_38 ----------------------------------------------------------------------------------------------------
7
1.0 1160047
2.0 1953232
3.0 1255315
4.0 294917
5.0 444856
6.0 162040
7.0 259028
Name: B_38, dtype: int64
D_114 ----------------------------------------------------------------------------------------------------
2
0.0 2038257
1.0 3316478
Name: D_114, dtype: int64
D_116 ----------------------------------------------------------------------------------------------------
2
0.0 5348109
1.0 6626
Name: D_116, dtype: int64
D_117 ----------------------------------------------------------------------------------------------------
7
-1.0 1456084
1.0 122967
2.0 666808
3.0 1166400
4.0 1138666
5.0 459290
6.0 344520
Name: D_117, dtype: int64
D_120 ----------------------------------------------------------------------------------------------------
2
0.0 4729723
1.0 625012
Name: D_120, dtype: int64
D_126 ----------------------------------------------------------------------------------------------------
3
-1.0 260898
0.0 891323
1.0 4262414
Name: D_126, dtype: int64
D_63 ----------------------------------------------------------------------------------------------------
6
CL 438390
CO 4119621
CR 930133
XL 6965
XM 10556
XZ 25786
Name: D_63, dtype: int64
D_64 ----------------------------------------------------------------------------------------------------
4
-1 37205
O 2913244
R 840112
U 1523448
Name: D_64, dtype: int64
D_66 ----------------------------------------------------------------------------------------------------
2
0.0 6288
1.0 617066
Name: D_66, dtype: int64
D_68 ----------------------------------------------------------------------------------------------------
7
0.0 15925
1.0 133122
2.0 220111
3.0 484442
4.0 477187
5.0 1201706
6.0 2782455
Name: D_68, dtype: int64
CPU times: user 8.76 s, sys: 1.13 s, total: 9.89 s
Wall time: 9.76 s
object features
customer_ID: customer id.S_2: dateD_63, D_64: categorical features
print(nacnt[nacnt['dtype']=='object']['feat'].values)
['D_64' 'customer_ID' 'D_63' 'S_2']
%%time
for c in nacnt[nacnt['dtype']=='object']['feat'].values:
df = dd.read_parquet(train_file, columns=[c], engine='pyarrow')
print(c, '-'*100)
display(df.head(5))
if c=='customer_ID':
t = df[c].value_counts().compute()
display(t.value_counts())
display(df[df['customer_ID']=='8034aa3a67acb152f472bd8036f4c579b559d046ba12d7a911d27abd1c4b080b'].head(20))
del df
gc.collect()
D_64 ----------------------------------------------------------------------------------------------------
| D_64 | |
|---|---|
| 0 | O |
| 1 | O |
| 2 | O |
| 3 | O |
| 4 | O |
customer_ID ----------------------------------------------------------------------------------------------------
| customer_ID | |
|---|---|
| 0 | 2e3fc76a68eeae6697b0a6b10f9288b7acaa678bbf99cd... |
| 1 | 2e3fc76a68eeae6697b0a6b10f9288b7acaa678bbf99cd... |
| 2 | 2e3fc76a68eeae6697b0a6b10f9288b7acaa678bbf99cd... |
| 3 | 2e3fc76a68eeae6697b0a6b10f9288b7acaa678bbf99cd... |
| 4 | 2e3fc76a68eeae6697b0a6b10f9288b7acaa678bbf99cd... |
13 386034
12 10623
10 6721
9 6411
8 6110
2 6098
11 5961
3 5778
6 5515
7 5198
1 5120
4 4673
5 4671
Name: customer_ID, dtype: int64
| customer_ID |
|---|
D_63 ----------------------------------------------------------------------------------------------------
| D_63 | |
|---|---|
| 0 | CR |
| 1 | CR |
| 2 | CR |
| 3 | CR |
| 4 | CR |
S_2 ----------------------------------------------------------------------------------------------------
| S_2 | |
|---|---|
| 0 | 2017-04-28 |
| 1 | 2017-05-25 |
| 2 | 2017-06-23 |
| 3 | 2017-07-29 |
| 4 | 2017-08-20 |
CPU times: user 9 s, sys: 3.34 s, total: 12.3 s
Wall time: 12.9 s
int features
- only one feature is int type:
B_31 - this feature should be treated as categorical feature as well
print(nacnt[nacnt['dtype']=='int32']['feat'].values)
['B_31']
%%time
for c in nacnt[nacnt['dtype']=='int32']['feat'].values:
df = dd.read_parquet(train_file, columns=[c], engine='pyarrow')
display(df[c].value_counts().compute().sort_index())
del df
gc.collect()
0 16907
1 5514544
Name: B_31, dtype: int64
CPU times: user 502 ms, sys: 52.3 ms, total: 555 ms
Wall time: 561 ms
float features
nacnt.head(2)
| feat | dtype | na_cnt | nunique | na_pct | |
|---|---|---|---|---|---|
| 108 | D_87 | float32 | 5527586 | 1 | 99.930127 |
| 111 | D_88 | float32 | 5525447 | 6004 | 99.891457 |
nacnt[(nacnt['dtype']=='float32') & (nacnt['nunique']>100) & (nacnt['na_pct']<20)]
| feat | dtype | na_cnt | nunique | na_pct | |
|---|---|---|---|---|---|
| 37 | S_7 | float32 | 1020544 | 4185390 | 18.449843 |
| 7 | S_3 | float32 | 1020544 | 4004312 | 18.449843 |
| 52 | D_62 | float32 | 758161 | 4519358 | 13.706367 |
| 19 | D_48 | float32 | 718725 | 4534865 | 12.993426 |
| 49 | D_61 | float32 | 598052 | 4529133 | 10.811847 |
| ... | ... | ... | ... | ... | ... |
| 79 | B_24 | float32 | 0 | 4960342 | 0.000000 |
| 77 | D_75 | float32 | 0 | 4446618 | 0.000000 |
| 75 | P_4 | float32 | 0 | 4702565 | 0.000000 |
| 73 | B_23 | float32 | 0 | 5300841 | 0.000000 |
| 95 | S_17 | float32 | 0 | 4996175 | 0.000000 |
143 rows × 5 columns
print(cat_feats)
cat_feats = cat_feats + ['B_31']
print(cat_feats)
['B_30', 'B_38', 'D_114', 'D_116', 'D_117', 'D_120', 'D_126', 'D_63', 'D_64', 'D_66', 'D_68']
['B_30', 'B_38', 'D_114', 'D_116', 'D_117', 'D_120', 'D_126', 'D_63', 'D_64', 'D_66', 'D_68', 'B_31']
float_feats = nacnt[nacnt['dtype']=='float32']['feat'].values.tolist()
print(len(float_feats))
float_feats = list((set(float_feats) - set(cat_feats)) - set(missing20) )
print(len(float_feats))
print(float_feats)
185
143
['R_17', 'B_40', 'R_27', 'S_18', 'B_13', 'B_33', 'R_20', 'S_6', 'R_23', 'R_16', 'B_24', 'D_125', 'D_44', 'D_91', 'D_71', 'P_2', 'B_15', 'D_103', 'S_12', 'D_144', 'D_123', 'D_94', 'D_70', 'D_39', 'P_4', 'S_23', 'R_12', 'S_5', 'D_72', 'B_27', 'B_6', 'D_89', 'D_143', 'D_80', 'B_3', 'B_28', 'R_11', 'B_14', 'B_1', 'D_124', 'D_109', 'B_25', 'B_36', 'B_5', 'B_18', 'D_61', 'R_13', 'B_37', 'S_7', 'D_104', 'B_26', 'B_4', 'R_6', 'D_133', 'B_21', 'S_19', 'D_115', 'R_18', 'D_45', 'D_69', 'S_24', 'D_84', 'S_17', 'B_12', 'D_52', 'R_24', 'D_127', 'R_14', 'D_113', 'D_83', 'D_141', 'B_10', 'S_22', 'D_96', 'R_15', 'S_25', 'D_54', 'D_60', 'D_59', 'S_11', 'R_8', 'D_74', 'R_4', 'D_118', 'D_62', 'B_7', 'S_15', 'B_2', 'R_28', 'S_26', 'D_119', 'D_86', 'D_81', 'D_93', 'R_3', 'B_16', 'B_9', 'D_107', 'D_78', 'D_140', 'S_13', 'B_11', 'D_47', 'R_1', 'D_55', 'R_22', 'D_102', 'D_112', 'D_131', 'B_32', 'R_10', 'R_7', 'R_19', 'D_41', 'D_130', 'B_23', 'R_5', 'D_121', 'B_19', 'P_3', 'B_8', 'D_79', 'D_122', 'S_3', 'R_25', 'D_92', 'D_58', 'D_51', 'B_41', 'S_8', 'B_22', 'D_139', 'R_2', 'D_48', 'D_145', 'D_129', 'B_20', 'S_16', 'S_20', 'D_128', 'D_75', 'D_65', 'R_21']
%%time
#features with negative values will not have the log transform plot
import matplotlib.pyplot as plt
import math
float_stats = []
ncols = 4
nrows = math.ceil(len(float_feats)*2/ncols)
# nrows = math.ceil(50*2/ncols)
# ncols = 4
# nrows = math.ceil(10*2/ncols)
#fig, axes = plt.subplots(nrows=nrows, ncols=ncols)
fig, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=(20, 360))
for i, c in enumerate(float_feats):
df = dd.read_parquet(train_file, columns=[c], engine='pyarrow')
#--calculate the stats ----------
item = [c, df[c].compute().min(), df[c].compute().max(), df[c].compute().mean(), df[c].compute().std(), df[c].compute().median(), df[c].compute().skew()]
for q in [0.05, 0.15, 0.25, 0.75, 0.85, 0.95]:
item.append(df[c].compute().quantile(q=q))
float_stats.append(item)
#--plot the graph------------------
df[c].compute().plot(ax=axes[i//2, (i%2)*2], kind='hist', bins=50)
axes[i//2, (i%2)*2].set_title(f'{c}')
if df.compute().min().values[0]>0:
df[c].compute().transform(np.log).plot(ax=axes[i//2,(i%2)*2 + 1], kind='hist', bins=50)
axes[i//2,(i%2)*2 + 1].set_title(f'log of {c}')
del df
gc.collect()
CPU times: user 15min 51s, sys: 1min 56s, total: 17min 47s
Wall time: 17min 41s

float_stats_df = pd.DataFrame(data=float_stats,
columns=['feat', 'min', 'max', 'mean', 'std', 'median', 'skew',
'quantile0.05', 'quantile0.15', 'quantile0.25', 'quantile0.75', 'quantile0.85', 'quantile0.95'])
float_stats_df
| feat | min | max | mean | std | median | skew | quantile0.05 | quantile0.15 | quantile0.25 | quantile0.75 | quantile0.85 | quantile0.95 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | R_17 | 1.066114e-09 | 1.001528 | 0.005319 | 0.006380 | 0.005031 | 26.054792 | 0.000503 | 0.001511 | 0.002519 | 0.007544 | 0.008551 | 0.009559 |
| 1 | B_40 | 1.201275e-08 | 5755.076172 | 0.203261 | 8.081345 | 0.058309 | 475.881531 | 0.003281 | 0.008622 | 0.017393 | 0.245154 | 0.402013 | 0.630622 |
| 2 | R_27 | -2.571099e-02 | 1.010000 | 0.893695 | 0.312307 | 1.004365 | -2.449320 | 0.015879 | 1.000420 | 1.001545 | 1.007182 | 1.008310 | 1.009437 |
| 3 | S_18 | 4.075928e-11 | 1.010000 | 0.031466 | 0.160546 | 0.005134 | 5.897257 | 0.000512 | 0.001542 | 0.002571 | 0.007701 | 0.008730 | 0.009757 |
| 4 | B_13 | 1.905850e-08 | 276.177826 | 0.100716 | 0.559384 | 0.029314 | 177.815186 | 0.002531 | 0.006215 | 0.009255 | 0.089415 | 0.151466 | 0.349563 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 138 | S_20 | 6.887991e-10 | 1.010000 | 0.017487 | 0.111088 | 0.005062 | 8.771165 | 0.000506 | 0.001521 | 0.002533 | 0.007592 | 0.008605 | 0.009619 |
| 139 | D_128 | 3.235349e-09 | 1.023472 | 0.584121 | 0.493150 | 1.000419 | -0.322798 | 0.001188 | 0.003570 | 0.005949 | 1.004735 | 1.006463 | 1.008185 |
| 140 | D_75 | 1.120811e-09 | 4.275118 | 0.171199 | 0.224214 | 0.074370 | 2.284789 | 0.001344 | 0.004032 | 0.006720 | 0.268856 | 0.342966 | 0.607340 |
| 141 | D_65 | 3.539404e-09 | 385.901642 | 0.039764 | 0.473098 | 0.005223 | 259.727264 | 0.000521 | 0.001568 | 0.002611 | 0.007836 | 0.008881 | 0.009927 |
| 142 | R_21 | 3.646872e-09 | 1.010000 | 0.021610 | 0.127847 | 0.005081 | 7.558036 | 0.000509 | 0.001523 | 0.002537 | 0.007624 | 0.008642 | 0.009661 |
143 rows × 13 columns
float_stats_df.to_csv('float_stats.csv', sep='|', index=False)