Reshaping data
Reference:
cheat sheet pdf
Load DataFrame
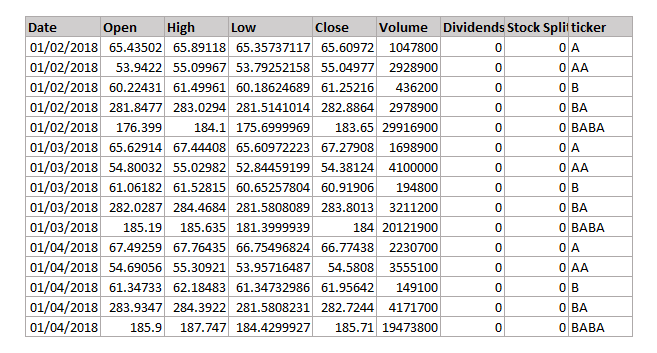
df = pd.read_csv('sample.csv')
df = df[df['Date']<='2018-01-04'].copy(deep=True)
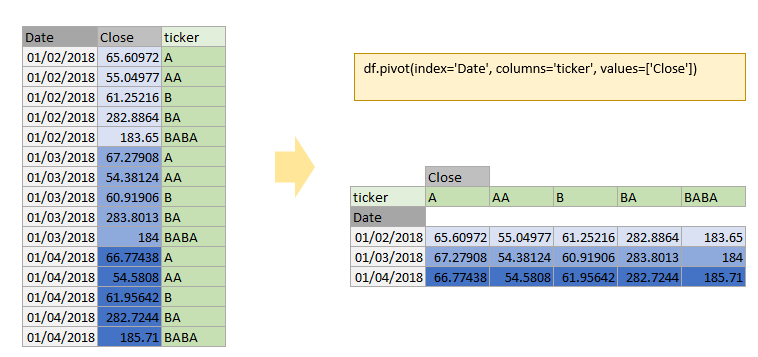
pivot:
reshape DataFrame by given index / column values
df.pivot(index='Date', columns='ticker', values=['Close'])
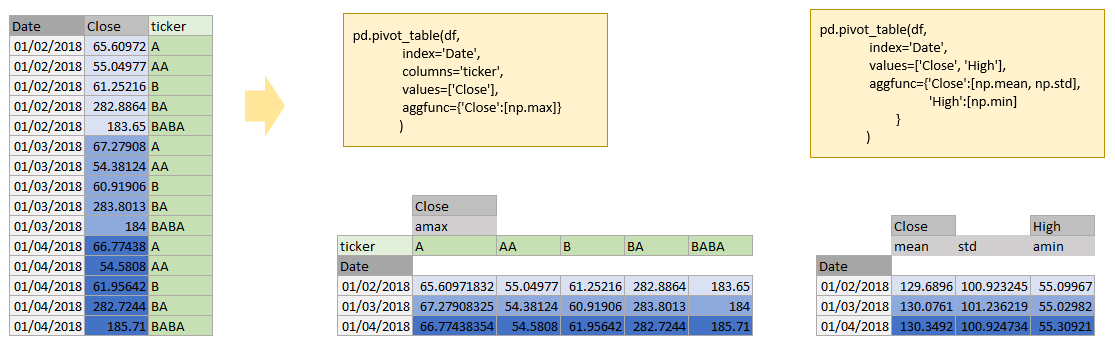
pivot_table
Create a spreadsheet-style pivot table as a DataFrame.
pd.pivot_table(df,
index='Date',
columns='ticker',
values=['Close'],
aggfunc={'Close':[np.max]}
)
pd.pivot_table(df,
index='Date',
values=['Close', 'High'],
aggfunc={'Close':[np.mean, np.std],
'High':[np.min]
}
)
melt
-Unpivot a DataFrame from wide to long format
#prepare data for melt operation
pivot_df = df.pivot(index='Date', columns='ticker', values=['Close']).reset_index()
pivot_df.columns = ['Date', 'A', 'AA', 'B', 'BA', 'BABA']
pivot_df
| Date | A | AA | B | BA | BABA |
| 0 | 2018-01-02 | 65.609718 | 55.049774 | 61.252163 | 282.886414 | 183.649994 |
| 1 | 2018-01-03 | 67.279083 | 54.381237 | 60.919060 | 283.801270 | 184.000000 |
| 2 | 2018-01-04 | 66.774384 | 54.580803 | 61.956425 | 282.724426 | 185.710007 |
pd.melt(pivot_df,
id_vars=['Date'],
value_vars=['A', 'AA', 'B', 'BA', 'BABA'],
var_name = 'ticker',
value_name='Close'
).sort_values(by='Date')

unstack
Pivot a level of the (necessarily hierarchical) index labels.- similar to
melt
#prepare data for unstack operation
pivot_df.set_index(keys=['Date'], inplace=True)
pivot_df
| A | AA | B | BA | BABA |
| Date | | | | | |
| 2018-01-02 | 65.609718 | 55.049774 | 61.252163 | 282.886414 | 183.649994 |
| 2018-01-03 | 67.279083 | 54.381237 | 60.919060 | 283.801270 | 184.000000 |
| 2018-01-04 | 66.774384 | 54.580803 | 61.956425 | 282.724426 | 185.710007 |
pivot_df.unstack().reset_index()

stack
Stack the prescribed level(s) from columns to index.
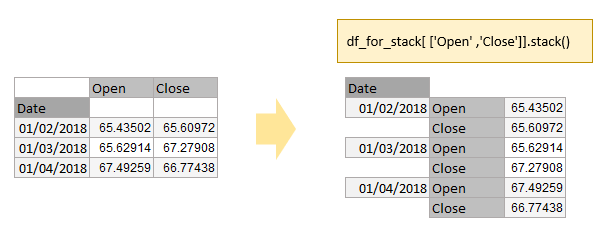
#prepare data for stack operation
df_for_stack = df.loc[df['ticker']=='A', ['Date','Open','Close']]
df_for_stack.set_index(keys=['Date'], inplace=True)
df_for_stack
df_for_stack[ ['Open' ,'Close']].stack()